Benchmarking hipSYCL with HeCBench on AMD hardware
HeCBench
HeCBench is a large benchmark collection that provides applications in various programming models, gathered from various sources. The fact that it does contain SYCL ports makes it interesting for the purpose of evaluating hipSYCL, as the performance of the SYCL version with hipSYCL can be compared to the native programming models. In this blog post, we’ll be looking into comparing the hipSYCL performance with native HIP performance on an AMD Radeon Pro VII.
Benchmark selection
HeCBench overall contains over 280 benchmarks, and hence evaluating all of them is very time-consuming. Some of them don’t run yet with hipSYCL, e.g. because they rely on DPC++-specific extensions or non-standard SYCL behavior (more details on these issues can be found in this paper), but the majority works. So, to simplify the problem at hand, we select the first ~30 benchmarks in alphabetical order that work with hipSYCL. Additionally, we include four benchmarks that we already had data on from prior work: XSBench, RSBench, md5hash and nbody.
Following these criteria, we have selected the following applications:
aligned-types
amgmk
aobench
asta
atomicCAS
atomicIntrinsics
atomicReduction
attention
babelstream
bezier-surface
binomial
bitonic-sort
bsearch
bspline-vgh
ccsd-trpdrv
clenergy
convolutionSeparable
crc64
damage
dp
dslash
expdist
extend2
extrema
fft
filter
floydwarshall
fpc
gamma-correction
XSBench
RSBench
md5hash
nbody
Some of these applications are more of functional tests rather than benchmarks (e.g. aligned-types), some are memory-bound (e.g. babelstream), and others are compute-bound (e.g. fft). So, we have a good mixture of different use cases at our hand, that are hopefully representative of common scenarios in the real world.
Results
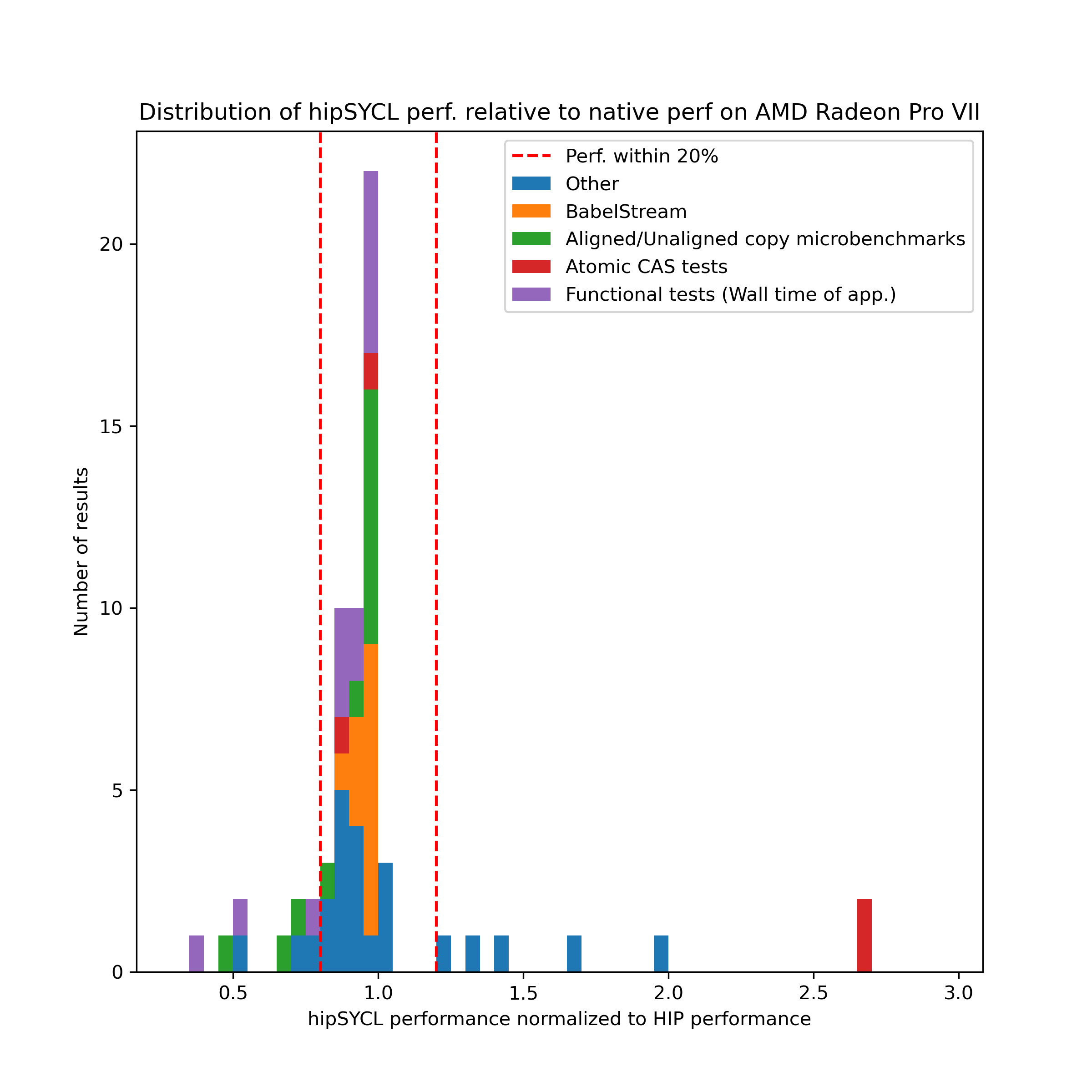
The plot below shows the relative performance between the hipSYCL results and the native HIP results. Some applications return more than one result, in which case multiple results are shown for one application. This is prominently the case for BabelStream. Where the application itself did not provide performance results (e.g. for some functional tests), the wall time of the application execution was measured. The vertical red lines indicate performance parity within 20%.
As can be seen, the vast majority of applications perform within 20% of the native HIP performance. Those applications that perform worse are almost exclusively applications that are not necessarily geared towards performance measurements such as aligned/unaligned copy microbenchmarks or functional tests.
On the other hand, there are also numerous cases where hipSYCL substantially outperforms HIP, such as aobench at almost twice the performance, and some CAS tests with an even higher relative performance. In fact, the CAS tests for an atomic maximum implementation even outperform HIP by over 20x, and are not shown in the plot in order to retain a reasonable axis range.
Conclusion
It is apparent that hipSYCL can reliably deliver good performance when looking at the HeCBench applications on the investigated AMD hardware. While there are (few) cases, where HIP outperforms hipSYCL, there are also cases where hipSYCL substantially outperforms HIP.